♥一些领域算法知识体系♥
♥一些领域算法知识体系♥
本系列主要总结下常见的某些领域的算法。@pdai
知识体系
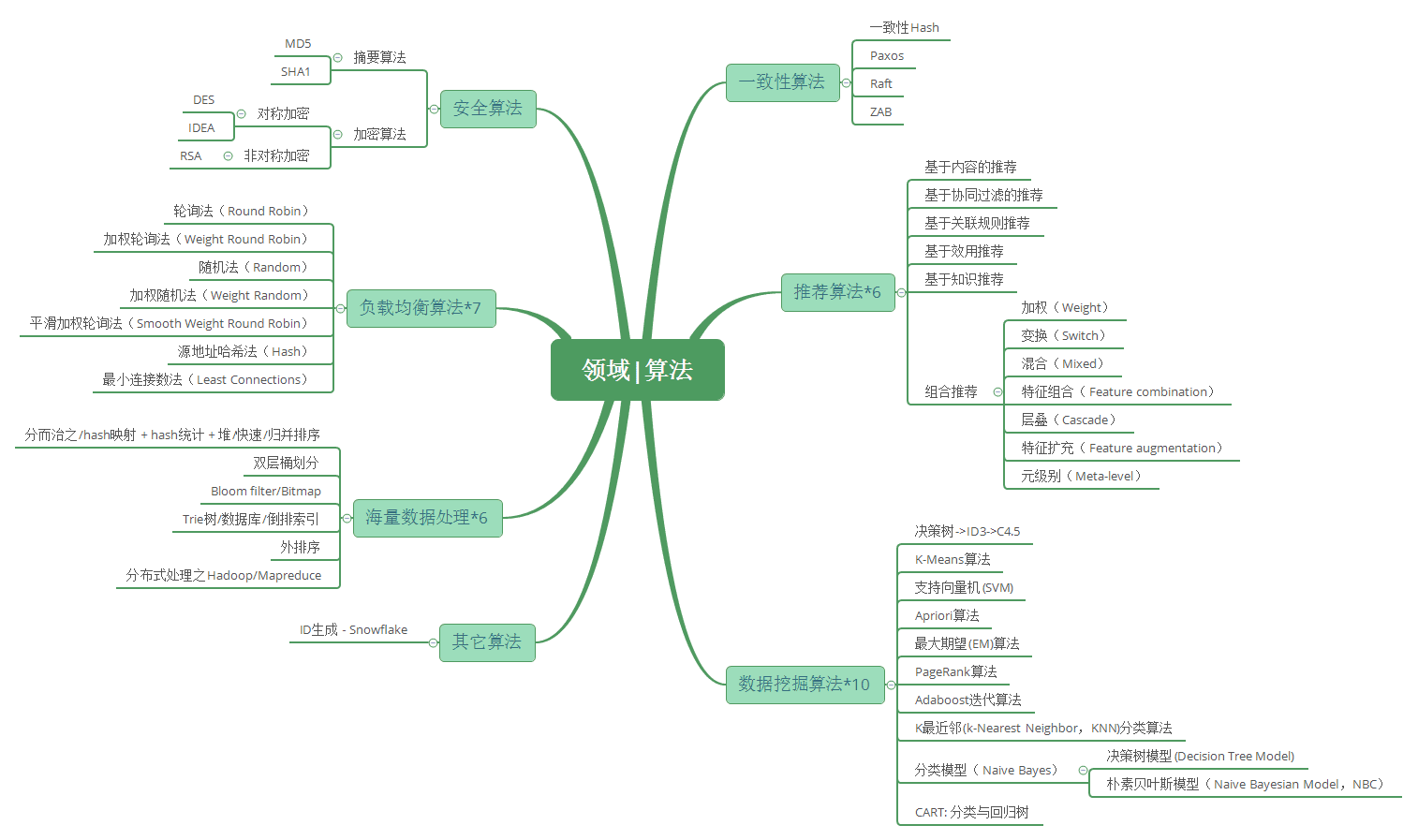
知识体系系统性梳理
相关文章
A. 领域算法 梳理知识点:在了解基础算法之后,我们还要学习和了解在不同专业领域有哪些特有的算法。这里不一定要求复杂度,而是要有知识面以及解决问题的思路。
B. 领域算法之 安全算法:主要包括摘要算法和加密算法两大类。
消息摘要算法的主要特征是加密过程不需要密钥,并且经过加密的数据无法被解密,目前可以解密逆向的只有CRC32算法,只有输入相同的明文数据经过相同的消息摘要算法才能得到相同的密文。消息摘要算法不存在密钥的管理与分发问题,适合于分布式网络上使用。
数据加密的基本过程就是对原来为明文的文件或数据按某种算法进行处理,使其成为不可读的一段代码为“密文”,使其只能在输入相应的密钥之后才能显示出原容,通过这样的途径来达到保护数据不被非法人窃取、阅读的目的。 该过程的逆过程为解密,即将该编码信息转化为其原来数据的过程
国密即国家密码局认定的国产密码算法。主要有SM1,SM2,SM3,SM4,SM7, SM9。
C. 领域算法之 字符串匹配算法:字符串匹配(String Matchiing)也称字符串搜索(String Searching)是字符串算法中重要的一种,是指从一个大字符串或文本中找到模式串出现的位置。
朴素的字符串匹配算法又称为暴力匹配算法(Brute Force Algorithm),最为简单的字符串匹配算法
Knuth-Morris-Pratt算法(简称KMP)是最常用的字符串匹配算法之一
各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法,效率非常高
上述字符串匹配算法(朴素的字符串匹配算法, KMP 算法, Boyer-Moore算法)均是通过对模式(Pattern)字符串进行预处理的方式来加快搜索速度。对 Pattern 进行预处理的最优复杂度为 O(m),其中 m 为 Pattern 字符串的长度。那么,有没有对文本(Text)进行预处理的算法呢?本文即将介绍一种对 Text 进行预处理的字符串匹配算法:后缀树(Suffix Tree)
D. 领域算法之 大数据处理:这里其实想让大家理解的是大数据处理的常用思路,而不是算法本身。
本文主要介绍大数据处理的一些思路
就是先映射,而后统计,最后排序:
分而治之/hash映射: 针对数据太大,内存受限,只能是: 把大文件化成(取模映射)小文件,即16字方针: 大而化小,各个击破,缩小规模,逐个解决hash_map统计: 当大文件转化了小文件,那么我们便可以采用常规的hash_map(ip,value)来进行频率统计。堆/快速排序: 统计完了之后,便进行排序(可采取堆排序),得到次数最多的IP。布隆过滤器有着广泛的应用,对于大量数据的“存不存在”的问题在空间上有明显优势,但是在判断存不存在是有一定的错误率(false positive),也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)
其实本质上还是分而治之的思想,重在“分”的技巧上!
适用范围: 第k大,中位数,不重复或重复的数字;基本原理及要点: 因为元素范围很大,不能利用直接寻址表,所以通过多次划分,逐步确定范围,然后最后在一个可以接受的范围内进行。适用范围: 数据量大,重复多,但是数据种类小可以放入内存;基本原理及要点: 实现方式,节点孩子的表示方式;扩展: 压缩实现适用范围: 大数据的排序,去重;基本原理及要点: 外排序的归并方法,置换选择败者树原理,最优归并树MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。但如果你要我再通俗点介绍,那么,说白了,Mapreduce的原理就是一个归并排序
E. 领域算法之 分布式算法:接着向大家介绍分布式算法,包括一致性Hash算法,经典的Paxos算法,Raft算法,ZAB算法等;顺便也介绍了经典用于全局ID生成的Snowflake算法。
本文总结下常见的分布式算法
一致性Hash算法是个经典算法,Hash环的引入是为解决
单调性(Monotonicity)的问题;虚拟节点的引入是为了解决平衡性(Balance)问题Paxos算法是Lamport宗师提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。自Paxos问世以来就持续垄断了分布式一致性算法,Paxos这个名词几乎等同于分布式一致性, 很多分布式一致性算法都由Paxos演变而来
Paxos是出了名的难懂,而Raft正是为了探索一种更易于理解的一致性算法而产生的。它的首要设计目的就是易于理解,所以在选主的冲突处理等方式上它都选择了非常简单明了的解决方案
ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议), 它应该是所有一致性协议中生产环境中应用最多的了。为什么呢?因为他是为 Zookeeper 设计的分布式一致性协议!
Snowflake,雪花算法是由Twitter开源的分布式ID生成算法,以划分命名空间的方式将 64-bit位分割成多个部分,每个部分代表不同的含义。这种就是将64位划分为不同的段,每段代表不同的涵义,基本就是时间戳、机器ID和序列数。为什么如此重要?因为它提供了一种ID生成及生成的思路,当然这种方案就是需要考虑时钟回拨的问题以及做一些 buffer的缓冲设计提高性能。
F. 领域算法之 其它算法汇总:最后概要性的了解常见的其它算法:负载均衡算法,推荐算法,数据挖掘或机器学习算法。因为有其专业性,一般总体上了解就够了。
本文主要介绍常用的负载均衡算法和Nginx中支持的负载均衡算法:轮询法(Round Robin),加权轮询法(Weight Round Robin),平滑加权轮询法(Smooth Weight Round Robin),随机法(Random),加权随机法(Weight Random),源地址哈希法(Hash),最小连接数法(Least Connections)
本文主要对推荐算法整体知识点做汇总,做到总体的理解;深入理解需要再看专业的材料
国际权威的学术组织the IEEE International Conference on Data Mining (ICDM) 2006年12月评选出了数据挖掘领域的十大经典算法: C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART
推荐学习
推荐博客园@刘建平Pinard 的机器学习,数据挖掘系列 在新窗口打开
推荐CSDN@July 的机器学习相关 在新窗口打开